

Optimizing Language Models: Decoding Griffin’s Local Attention and Memory Efficiency
6 May 2025
Explores how Griffin’s local attention and recurrent layers outperform traditional Transformers, improving language modeling at scale and faster inference.

Overcoming HBM-VMEM Bottlenecks in TPU-v3 Recurrent Workloads
6 May 2025
Novel recurrence gates and complex-valued units boost stability and efficiency in linear recurrent models, optimized for TPU-v3 hardware.

Hawk and Griffin: Efficient RNN Models Redefining AI Performance
14 Jan 2025
This research introduces Hawk and Griffin models, efficient RNN alternatives to Transformers, with reduced latency and strong long-sequence performance.

RNNs vs. Transformers: Innovations in Scalability and Efficiency
14 Jan 2025
This research explores scalable RNN and SSM innovations, comparing their efficiency and performance to Transformers and linear attention techniques.

Hawk and Griffin: Mastering Long-Context Extrapolation in AI
14 Jan 2025
This research shows Hawk and Griffin models excel at long-context extrapolation, predicting tokens for sequences 4x longer than training.
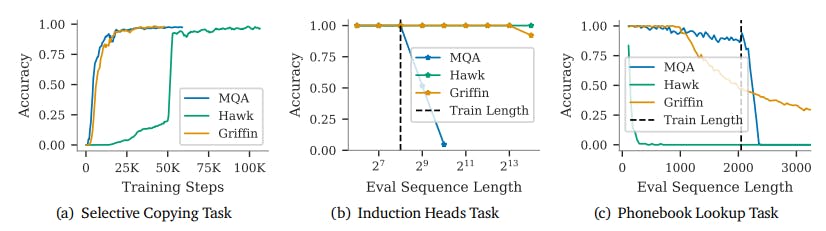
Griffin Model: Advancing Copying and Retrieval in AI Tasks
14 Jan 2025
This research shows Griffin excels in copying and retrieval tasks, outperforming Hawk and Transformers in extrapolation for longer sequences.

Hawk and Griffin Models: Superior Latency and Throughput in AI Inference
14 Jan 2025
This research shows Hawk and Griffin outperform MQA Transformers in latency and throughput, excelling in long-sequence and large-batch inference.
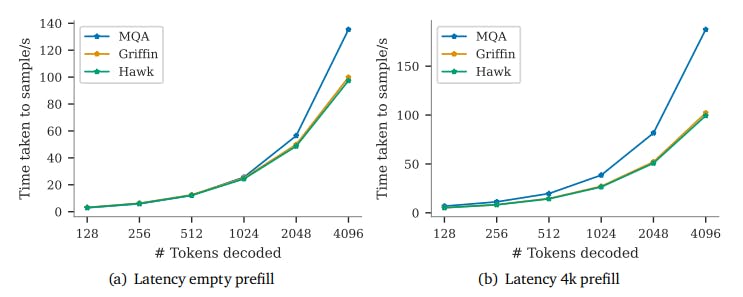
Recurrent Models: Enhancing Latency and Throughput Efficiency
14 Jan 2025
This research shows recurrent models reduce cache size, improving latency and throughput over Transformers for long sequences.

Recurrent Models: Decoding Faster with Lower Latency and Higher Throughput
14 Jan 2025
This research shows recurrent models excel in decoding, offering lower latency and higher throughput than Transformers, especially for long sequences.